Como construí esta aplicação usando ferramentas de IA
Motivação
Comecei a usar Duplicati como ferramenta de backup para meus servidores domésticos. Testei o painel oficial do Duplicati e Duplicati Monitoring, mas tinha dois requisitos principais: (1) auto-hospedado; e (2) uma API exposta para integração com Homepage, pois a utilizo para a página inicial do meu home lab.
Também tentei conectar diretamente a cada servidor Duplicati na rede, mas o método de autenticação não era compatível com Homepage (ou não consegui configurá-lo adequadamente).
Como também estava experimentando com ferramentas de IA para codificação, decidi tentar usar IA para construir esta ferramenta. Aqui está o processo que utilizei...
Ferramentas utilizadas
- Para a UI: Google's Firebase Studio
- Para a implementação: Cursor (https://www.cursor.com/)
Usei Firebase para a interface, mas você também pode usar v0.app ou qualquer outra ferramenta para gerar o protótipo. Usei Cursor para gerar a implementação, mas você pode usar outras ferramentas, como VS Code/Copilot, Windsurf, ...
IU
Criei um novo projeto no Firebase Studio e usei este prompt no recurso "Prototype an app with AI":
Uma aplicação de painel web usando tailwind/react para consolidar em um banco de dados sqllite3 o resultado de backup enviado pela solução de backup duplicati usando a opção --send-http-url (formato json) de várias máquinas, mantendo o rastreamento do status do backup, tamanho, tamanhos de upload.
A primeira página do painel deve ter uma tabela com o último backup de cada máquina, incluindo o nome da máquina, número de backups armazenados no banco de dados, o status do último backup, duração (hh:mm:ss), número de avisos e erros.
Ao clicar em uma linha de máquina, mostrar uma página de detalhes da máquina selecionada com uma lista dos backups armazenados (paginada), incluindo o nome do backup, data e hora do backup, incluindo há quanto tempo foi, o status, número de avisos e erros, número de arquivos, o tamanho dos arquivos, tamanho enviado e o tamanho total do armazenamento. Também incluir na página de detalhes um gráfico usando Tremor com a evolução dos campos: tamanho enviado; duração em minutos, número de arquivos examinados, tamanho dos arquivos examinados. O gráfico deve plotar um campo por vez, com uma caixa de seleção para escolher o campo desejado a plotar. Além disso, o gráfico deve apresentar todos os backups armazenados no banco de dados, não apenas os mostrados na tabela paginada.
A aplicação deve expor um endpoint de api para receber o post do servidor duplicati e outro endpoint de api para recuperar todos os detalhes do último backup de uma máquina como um json.
O design deve ser moderno, responsivo e incluir ícones e outros auxílios visuais para facilitar a leitura. O código deve ser limpo, conciso e fácil de manter. Use ferramentas modernas como pnpm para lidar com dependências.
A aplicação deve ter um tema escuro e claro selecionável.
O banco de dados deve armazenar estes campos recebidos pelo json do duplicati:
"{ "Data": { "DeletedFiles": 0, "DeletedFolders": 0, "ModifiedFiles": 0, "ExaminedFiles": 15399, "OpenedFiles": 1861, "AddedFiles": 1861, "SizeOfModifiedFiles": 0, "SizeOfAddedFiles": 13450481, "SizeOfExaminedFiles": 11086692615, "SizeOfOpenedFiles": 13450481, "NotProcessedFiles": 0, "AddedFolders": 419, "TooLargeFiles": 0, "FilesWithError": 0, "ModifiedFolders": 0, "ModifiedSymlinks": 0, "AddedSymlinks": 0, "DeletedSymlinks": 0, "PartialBackup": false, "Dryrun": false, "MainOperation": "Backup", "ParsedResult": "Success", "Interrupted": false, "Version": "2.1.0.5 (2.1.0.5_stable_2025-03-04)", "EndTime": "2025-04-21T23:46:38.3568274Z", "BeginTime": "2025-04-21T23:45:46.9712217Z", "Duration": "00:00:51.3856057", "WarningsActualLength": 0, "ErrorsActualLength": 0, "BackendStatistics": { "BytesUploaded": 8290314, "BytesDownloaded": 53550393, "KnownFileSize": 9920312634, "LastBackupDate": "2025-04-22T00:45:46+01:00", "BackupListCount": 6, "ReportedQuotaError": false, "ReportedQuotaWarning": false, "MainOperation": "Backup", "ParsedResult": "Success", "Interrupted": false, "Version": "2.1.0.5 (2.1.0.5_stable_2025-03-04)", "BeginTime": "2025-04-21T23:45:46.9712252Z", "Duration": "00:00:00", "WarningsActualLength": 0, "ErrorsActualLength": 0 } }, "Extra": { "OperationName": "Backup", "machine-id": "66f5ffc7ff474a73a3c9cba4ac7bfb65", "machine-name": "WSJ-SER5", "backup-name": "WSJ-SER5 Local files", "backup-id": "DB-2" } } "
isto gerou um App Blueprint, que então modifiquei ligeiramente (conforme abaixo) antes de clicar em Prototype this App:
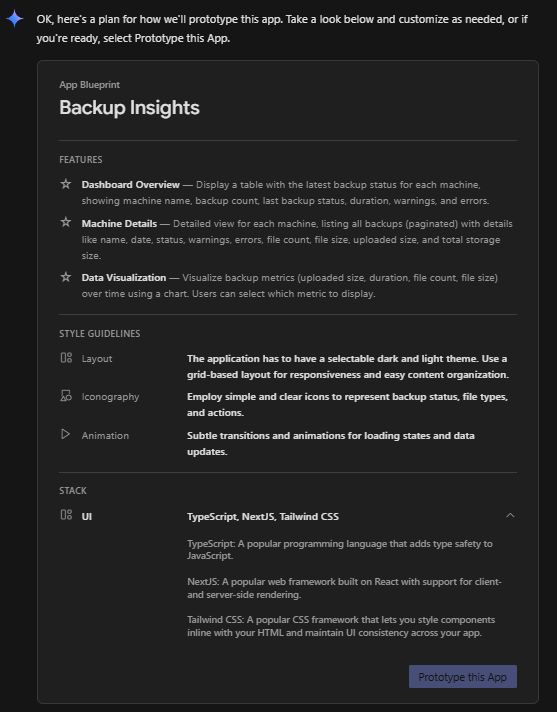
Posteriormente, usei esses prompts para ajustar e refinar o design e o comportamento:
remova o botão "Ver detalhes" da página de visão geral do painel e o link no nome da máquina, se o usuário clicar em qualquer lugar na linha, ele mostrará a página de detalhes.
quando apresentar tamanhos em bytes, use uma escala automática (KB, MB, GB, TB).
na página de detalhes, mova o gráfico após a tabela. Altere a cor do gráfico de barras para outra cor compatível com os temas Claro e Escuro.
na página de detalhes, reduza o número de linhas para apresentar 5 backups por página.
no painel de visão geral, coloque um resumo no topo com o número de máquinas no banco de dados, número total de backups de todas as máquinas, o tamanho total enviado de todos os backups e armazenamento total usado por todas as máquinas. Inclua ícones para facilitar a visualização.
por favor, persista o tema selecionado pelo usuário. além disso, adicione algumas margens laterais e faça a interface usar 90% da largura disponível.
no cartão de cabeçalho de detalhes da máquina, incluir um resumo com o total de backups armazenados para esta máquina, uma estatística do status do backup, o número de avisos e erros do último backup, a duração média em hh:mm:ss, o tamanho total enviado de todos os backups e o tamanho de armazenamento usado com base nas informações do último backup recebidas.
tornar o resumo menor e mais compacto para reduzir o espaço utilizado.
ao apresentar a data do último backup, mostrar na mesma célula, em uma fonte pequena e cinza, o tempo decorrido desde que o backup aconteceu (por exemplo, x minuto atrás, x horas atrás, x dias atrás, x semanas atrás, x meses atrás, x anos atrás).
no painel de visão geral, coloque a data do último backup antes do status do último backup
Após iterar por esses prompts, o Firebase gerou o protótipo conforme mostrado nas capturas de tela abaixo:
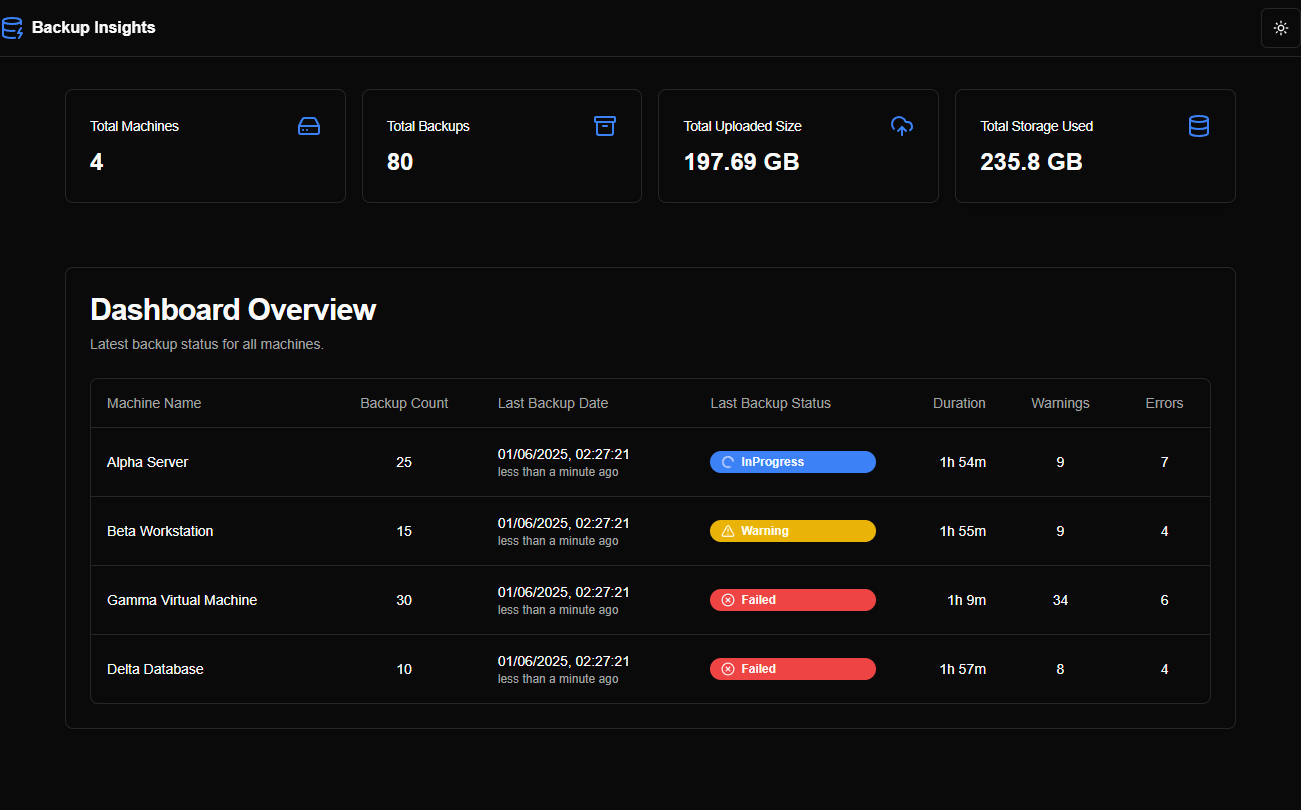
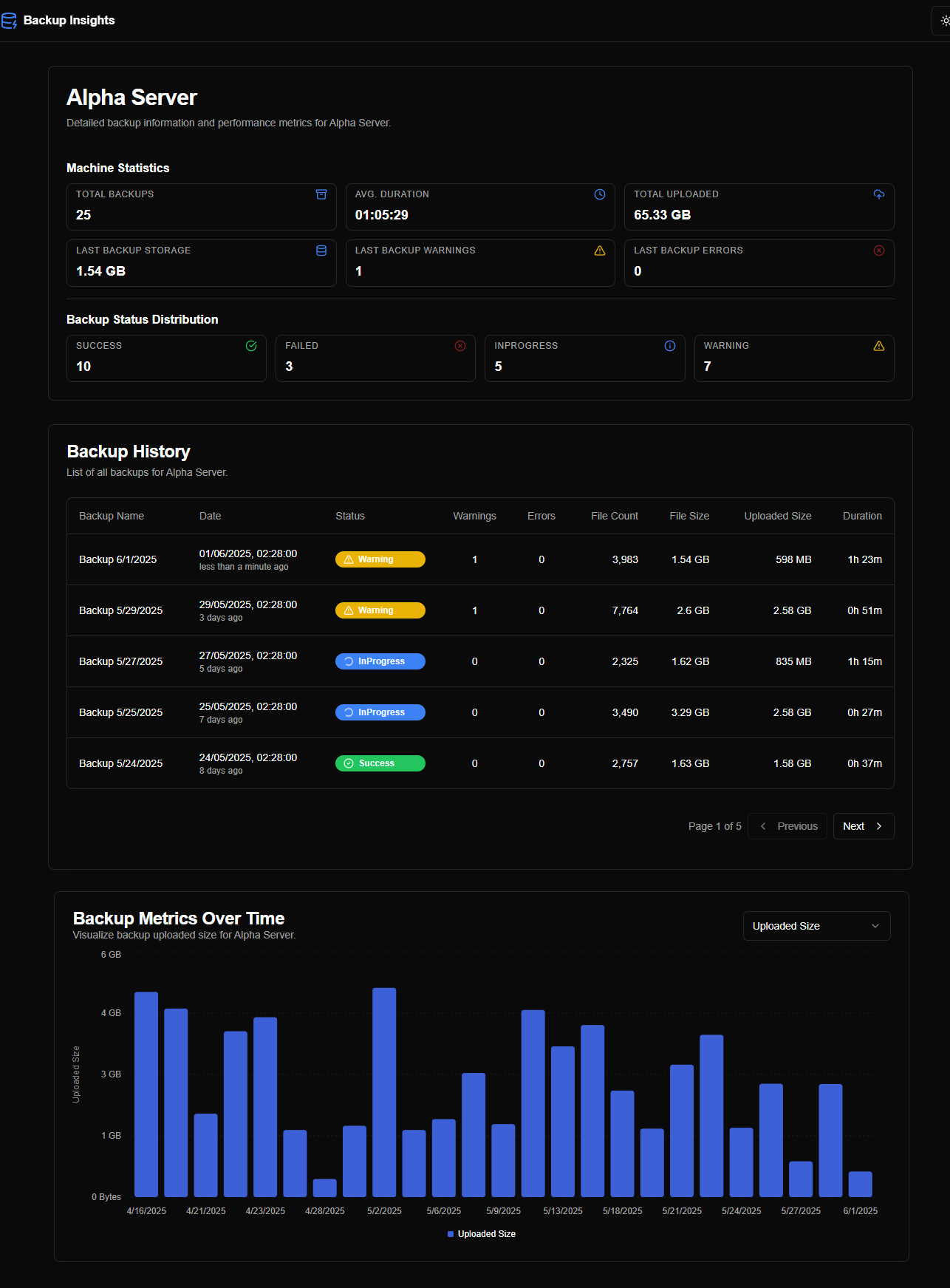
Um ponto interessante foi que, desde a primeira interação, o Firebase Studio gerou dados aleatórios para popular as páginas/gráficos, fazendo o protótipo funcionar como uma aplicação em tempo real.
Após concluir o protótipo inicial, acessei o código-fonte clicando no botão </> na interface. Em seguida, usei a extensão Git para exportar o código e enviá-lo para um repositório privado no GitHub.
Backend
Configuração
Baixei o código do GitHub (usando o comando git clone) para uma pasta local (no meu caso, um Raspberry Pi 5 executando Linux) e instalei as dependências Node.js, npm e pnpm. Veja mais detalhes em DEVELOPMENT.md.
Configurei o Cursor para acessar a pasta de código da minha máquina Windows usando uma conexão SSH.
Copiei uma amostra do JSON enviado pelo Duplicati para um arquivo (consulte o documento relatório de backup de exemplo), limpando alguns campos indesejados.
Implementação
Usei um prompt inicial para começar a implementação, focando em persistência, correções e novos recursos. Foi um processo longo, mas muito interessante.
Usando IA para gerar o prompt
Criei um prompt detalhado usando Cursor Chat (modo Manual, modelo Auto):
melhore este texto como um prompt para a ferramenta Cursor AI gerar a implementação de um protótipo de aplicação:
por favor, crie um plano e gere a implementação completa de um protótipo de aplicação Next.js a partir desta base de código. Sua implementação deve analisar minuciosamente a base de código fornecida para manter a estética visual exata, experiência de usuário e fluxo de navegação. Para armazenamento de dados, utilize SQLite3. Gere o banco de dados e popule-o utilizando a estrutura e conteúdo encontrados no documento relatório de backup de exemplo, garantindo que cada campo do JSON seja totalmente integrado e persistido.
A IA gerou o seguinte prompt:
Crie um plano de implementação abrangente para um protótipo de aplicação Next.js com os seguintes requisitos:
- Stack Técnico:
Next.js 14+ com App Router
TypeScript para segurança de tipos
SQLite3 para persistência de dados
TailwindCSS para estilo
React Server Components quando apropriado
Componentes cliente para elementos interativos
- Design de Banco de Dados:
Analise o documento de relatório de backup de exemplo para criar um esquema SQLite ideal
Projete tabelas para armazenar eficientemente todos os dados de backup
Inclua índices para consultas comuns
Implemente validação de dados e segurança de tipos
- Estrutura da Aplicação:
Implemente a UI/UX exata da base de código fornecida
Crie componentes reutilizáveis para elementos comuns
Configure o roteamento adequado usando App Router
Implemente layouts responsivos
Adicione suporte a tema claro/escuro
- Funcionalidades Principais:
Painel com visão geral da tabela de status de máquinas
Visualizar detalhado de máquina com Histórico de backups
Visualização de dados usando gráficos
Atualizações de status de backup em tempo real
Tratamento adequado de erros e estados de carregamento
- Gerenciamento de Dados:
- Crie rotas de API para operações de dados
- Implemente estratégias eficientes de busca de dados
- Adicione validação adequada de dados
- Inclua tratamento de erros para operações de banco de dados
Forneça um plano de implementação detalhado que cubra todos esses aspectos mantendo o design visual existente e a experiência do usuário.
Copiei o prompt gerado para a área de transferência.
Inicie a jornada de implementação
Criei um novo chat clicando no botão +, alternei para o modo Agent e colei o prompt usando Ctrl+Shift+V (como texto).
Após o plano ser gerado, digitei please, implement this plan no chat para começar a implementação.
Incluí apenas o ponto de partida, pois não registrei todos os prompts utilizados. Havia muitos deles.
Notas
- Alguns modelos podem travar ao corrigir bugs. "claude-3.5" e "claude-4" geralmente são melhores, mas às vezes é necessário tentar outro modelo (GPT, Gemini, etc.). Para bugs ou erros complexos, use um prompt para analisar as possíveis causas do erro em vez de simplesmente pedir para corrigi-lo.
- Ao fazer modificações complexas, use um prompt para criar um plano e depois peça ao agente de IA que o implemente. Isso sempre funciona melhor.
- Seja específico ao alterar o código-fonte. Se possível, selecione a parte relevante do código no editor e pressione Ctrl+L para incluí-la no chat como contexto.
- Inclua também uma referência ao arquivo que você está mencionando no chat para ajudar o agente de IA a se concentrar na parte relevante do código e evitar alterações em outras partes.
- Tenho a tendência de antropomorfizar o agente de IA, já que ele persistentemente usa 'nós', 'nosso código' e 'você gostaria que eu...'. Isso também é para melhorar minhas chances de sobrevivência caso (ou quando) o Skynet se torne senciente e o Exterminador seja inventado.
- Às vezes, use Gemini, Deepseek, ChatGPT, Manus,... para gerar prompts com instruções melhores para o agente de IA.