Cómo construí esta aplicación utilizando herramientas de IA
Motivación
Comencé a usar Duplicati como herramienta de backup para mis servidores domésticos. Probé el panel de control oficial de Duplicati y Duplicati Monitoring, pero tenía dos requisitos principales: (1) auto-alojado; y (2) una API expuesta para integración con Homepage, ya que la utilizo para la página de inicio de mi laboratorio doméstico.
También intenté conectarme directamente a cada servidor Duplicati en la red, pero el método de autenticación no era compatible con Homepage (o no fui capaz de configurarlo correctamente).
Como también estaba experimentando con herramientas de código de IA, decidí intentar usar IA para construir esta herramienta. Aquí está el proceso que utilicé...
Herramientas utilizadas
- Para la interfaz de usuario: Google's Firebase Studio
- Para la implementación: Cursor (https://www.cursor.com/)
Utilicé Firebase para la interfaz de usuario, pero también puedes usar v0.app o cualquier otra herramienta para generar el prototipo. Utilicé Cursor para generar la implementación, pero puede usar otras herramientas, como VS Code/Copilot, Windsurf, ...
IU
Creé un nuevo proyecto en Firebase Studio y utilicé este prompt en la función "Prototype an app with AI":
Una aplicación de panel de control web utilizando tailwind/react para consolidar en una base de datos sqllite3 los resultados de backup enviados por la solución de backup duplicati utilizando la opción --send-http-url (formato json) de varias máquinas, manteniendo un seguimiento del Estado del último backup, tamaño, tamaños de carga.
La primera página del Panel de control debe tener una tabla con el Último backup de cada máquina, incluyendo el nombre de la máquina, número de backups almacenados en la base de datos, el Estado del último backup, Duración (hh:mm:ss), Número de advertencias y Errores.
Al hacer clic en una línea de máquina, mostrar una página de Detalles de la máquina seleccionada con una lista de los backups almacenados (paginados), incluyendo el Nombre de backup, fecha y hora del backup, incluyendo cuánto tiempo hace, el Estado, Número de advertencias y Errores, número de Archivos, el Tamaño de los Archivos, Tamaño Enviado y el Tamaño Total del Almacenamiento. También incluir en la página de Detalles un gráfico utilizando Tremor con la evolución de los campos: Tamaño cargado; Duración en minutos, número de Archivos examinados, Tamaño de los Archivos examinados. El gráfico debe mostrar un campo a la vez, con un cuadro desplegable para Seleccionar el campo deseado a mostrar. Además, el gráfico debe presentar todos los backups almacenados en la base de datos, no solo los que se muestran en la tabla paginada.
La aplicación debe exponer un endpoint de api para recibir el post del Servidor duplicati y otro endpoint de api para recuperar todos los Detalles del Último backup de una máquina como JSON.
El diseño debe ser moderno, responsivo e incluir iconos y otras ayudas visuales para facilitar la lectura. El código debe ser limpio, conciso y fácil de mantener. Utilice herramientas modernas como pnpm para gestionar las dependencias.
La aplicación debe tener un Tema seleccionable Oscuro y Claro.
La base de datos debe almacenar estos campos recibidos por el JSON de duplicati:
"{ "Data": { "DeletedFiles": 0, "DeletedFolders": 0, "ModifiedFiles": 0, "ExaminedFiles": 15399, "OpenedFiles": 1861, "AddedFiles": 1861, "SizeOfModifiedFiles": 0, "SizeOfAddedFiles": 13450481, "SizeOfExaminedFiles": 11086692615, "SizeOfOpenedFiles": 13450481, "NotProcessedFiles": 0, "AddedFolders": 419, "TooLargeFiles": 0, "FilesWithError": 0, "ModifiedFolders": 0, "ModifiedSymlinks": 0, "AddedSymlinks": 0, "DeletedSymlinks": 0, "PartialBackup": false, "Dryrun": false, "MainOperation": "Backup", "ParsedResult": "Success", "Interrupted": false, "Version": "2.1.0.5 (2.1.0.5_stable_2025-03-04)", "EndTime": "2025-04-21T23:46:38.3568274Z", "BeginTime": "2025-04-21T23:45:46.9712217Z", "Duration": "00:00:51.3856057", "WarningsActualLength": 0, "ErrorsActualLength": 0, "BackendStatistics": { "BytesUploaded": 8290314, "BytesDownloaded": 53550393, "KnownFileSize": 9920312634, "LastBackupDate": "2025-04-22T00:45:46+01:00", "BackupListCount": 6, "ReportedQuotaError": false, "ReportedQuotaWarning": false, "MainOperation": "Backup", "ParsedResult": "Success", "Interrupted": false, "Version": "2.1.0.5 (2.1.0.5_stable_2025-03-04)", "BeginTime": "2025-04-21T23:45:46.9712252Z", "Duration": "00:00:00", "WarningsActualLength": 0, "ErrorsActualLength": 0 } }, "Extra": { "OperationName": "Backup", "machine-id": "66f5ffc7ff474a73a3c9cba4ac7bfb65", "machine-name": "WSJ-SER5", "backup-name": "WSJ-SER5 Local files", "backup-id": "DB-2" } } "
esto generó un App Blueprint, que luego modifiqué ligeramente (como se muestra a continuación) antes de hacer clic en Prototype this App:

Posteriormente utilicé estos mensajes para ajustar y refinar el diseño y el comportamiento:
eliminar el botón "Ver detalles" de la página de resumen del panel de control y el enlace en el nombre de la máquina, si el usuario hace clic en cualquier lugar de la fila, se mostrará la página de detalles.
cuando se presenten tamaños en bytes, utilizar una escala automática (KB, MB, GB, TB).
en la página de detalle, mueva el gráfico después de la tabla. Cambie el color del gráfico de barras a otro color compatible con los temas claro y oscuro.
en la página de detalle, reducir el número de filas para presentar 5 backups por página.
en el resumen del panel de control, ponga un resumen en la parte superior con el número de máquinas en la base de datos, el número total de backups de todas las máquinas, el total enviado de todas las copias de seguridad y el almacenamiento total usado por todas las máquinas. Incluya iconos para facilitar la visualización.
por favor, persista el tema seleccionado por el usuario. además, añada algunos márgenes laterales y haga que la interfaz de usuario utilice el 90% del ancho disponible.
en la tarjeta de encabezado de detalles de la máquina, incluir un resumen con el total de backups almacenados para esta máquina, una estadística del estado del backup, el número de advertencias y errores del último backup, la duración promedio en hh:mm:ss, el total enviado de todas las copias de seguridad y el tamaño de almacenamiento usado basado en la última información del backup recibida.
hacer el resumen más pequeño y compacto para reducir la huella utilizada.
cuando se presenta la fecha del último backup, mostrar en la misma celda, en una fuente pequeña de color gris, el tiempo transcurrido desde que ocurrió el backup (por ejemplo, hace x minuto, hace x horas, hace x días, hace x semanas, hace x meses, hace x años).
en el resumen del panel de control poner fecha del último backup antes del estado del último backup
Después de iterar a través de estos prompts, Firebase generó el prototipo como se muestra en las capturas de pantalla a continuación:
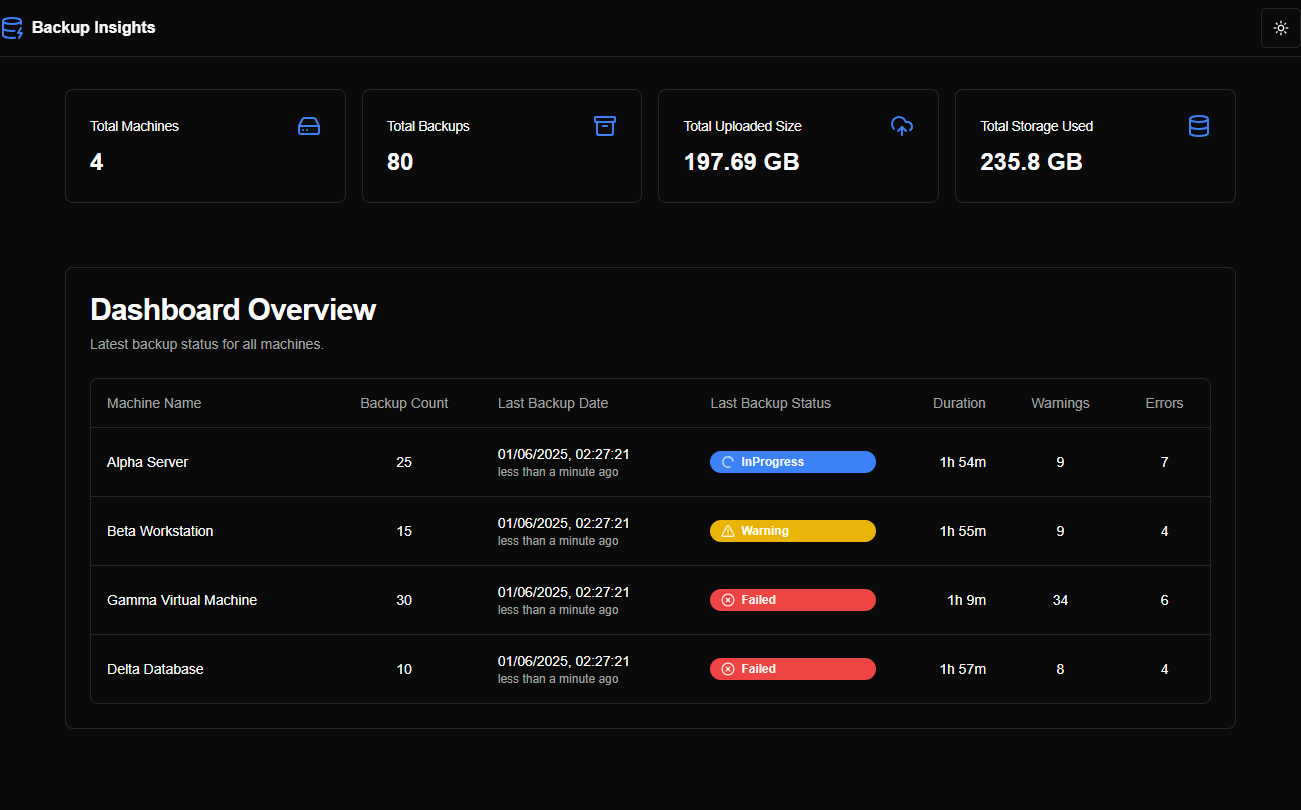
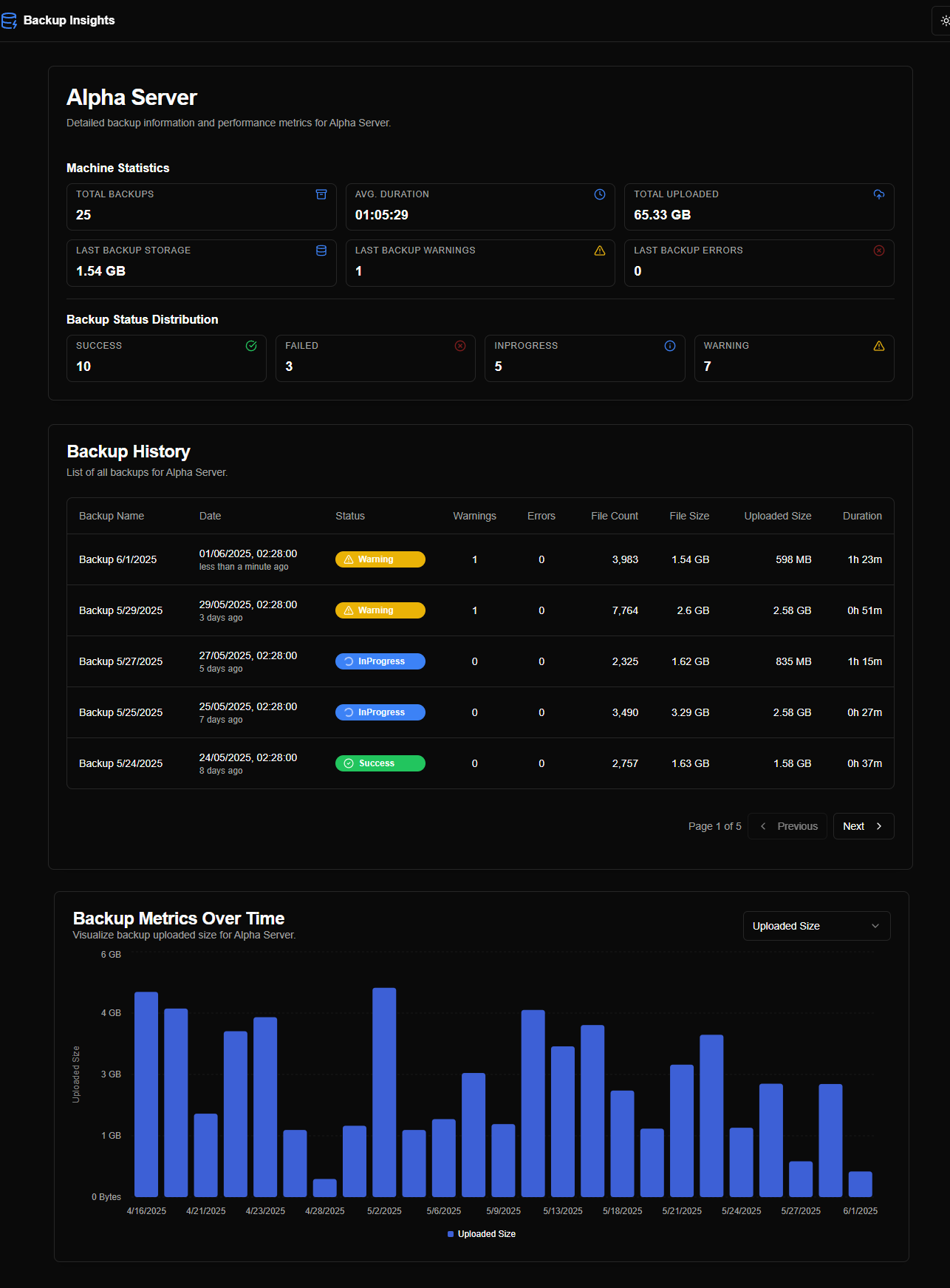
Un punto interesante fue que, desde la primera interacción, Firebase Studio generó datos aleatorios para completar las páginas/gráficos, haciendo que el prototipo funcionara como una aplicación en vivo.
Después de completar el prototipo inicial, accedí al código fuente haciendo clic en el botón </> en la interfaz. Luego utilicé la extensión de Git para exportar el código e insertarlo en un repositorio privado en GitHub.
Backend
Configuración
Descargué el código de GitHub (usando el comando git clone) a una carpeta local (en mi caso, una Raspberry Pi 5 ejecutando Linux) e instalé las dependencias Node.js, npm y pnpm. Consulte más detalles en DEVELOPMENT.md.
Configuré Cursor para acceder a la carpeta de código desde mi máquina Windows utilizando una conexión SSH.
Copié una muestra del JSON enviado por Duplicati en un archivo (consulte el documento informe de backup de ejemplo), eliminando algunos campos no deseados.
Implementación
Utilicé un mensaje inicial para comenzar la implementación, enfocándome en la persistencia, correcciones y nuevas funcionalidades. Fue un proceso largo pero muy interesante.
Usar IA para generar el prompt
Creé un aviso detallado usando Cursor Chat (modo Manual, modelo Auto):
mejore este texto como un prompt para la herramienta Cursor AI para generar la implementación de un prototipo de aplicación:
por favor cree un plan y genere la implementación completa de un prototipo de aplicación Next.js a partir de esta base de código. Su implementación debe analizar exhaustivamente la base de código proporcionada para mantener la estética visual exacta, la experiencia del usuario y el flujo de navegación. Para el almacenamiento de datos, utilice SQLite3. Genere la base de datos y complétela utilizando la estructura y el contenido que se encuentran en el documento informe de backup de ejemplo, asegurando que cada campo del JSON esté completamente integrado y persistido.
La IA generó el siguiente prompt:
Crear un plan de implementación exhaustivo para un prototipo de aplicación Next.js con los siguientes requisitos:
- Stack técnico:
Next.js 14+ con App Router
TypeScript para seguridad de tipos
SQLite3 para persistencia de datos
TailwindCSS para estilos
React Server Components donde sea apropiado
Componentes cliente para elementos interactivos
- Diseño de base de datos:
Analizar el documento de informe de backup de ejemplo para crear un esquema SQLite óptimo
Diseñar tablas para almacenar eficientemente todos los datos de backup
Incluir índices para consultas comunes
Implementar validación de datos y seguridad de tipos
- Estructura de la aplicación:
Implementar la interfaz de usuario exacta del código base proporcionado
Crear componentes reutilizables para elementos comunes
Configurar el enrutamiento adecuado usando App Router
Implementar diseños responsivos
Añadir soporte para tema claro/oscuro
- Características principales:
Resumen del panel de control con tabla de estado de máquinas
Vista detallada de máquina con historial de backups
Visualización de datos mediante gráficos
Actualizaciones de estado de backup en tiempo real
Manejo adecuado de errores y estados de carga
- Gestión de datos:
- Crear rutas API para operaciones de datos
- Implementar estrategias eficientes de obtención de datos
- Añadir validación adecuada de datos
- Incluir manejo de errores para operaciones de base de datos
Proporcione un plan de implementación detallado que cubra todos estos aspectos mientras se mantiene el diseño visual existente y la experiencia del usuario.
He copiado el mensaje generado al portapapeles.
Inicia el viaje de implementación
Creé un nuevo chat haciendo clic en el botón +, cambié al modo Agent y pegué el prompt usando Ctrl+Shift+V (como texto).
Después de que se generó el plan, escribí please, implement this plan en el chat para comenzar la implementación.
Solo incluí el punto de partida ya que no registré todos los indicadores utilizados. Había muchos de ellos.
Notas
- Algunos modelos pueden quedarse atascados al corregir errores. "claude-3.5" y "claude-4" suelen funcionar mejor, pero a veces hay que probar con otro modelo (GPT, Gemini, etc.). Para errores o fallos complejos, utiliza un prompt para analizar las posibles causas del error en lugar de simplemente pedir que lo corrija.
- Al realizar modificaciones complejas, utiliza un prompt para crear un plan y luego pide al agente de IA que lo implemente. Esto siempre funciona mejor.
- Sé específico al cambiar el código fuente. Si es posible, selecciona la parte relevante del código en el editor y presiona Ctrl+L para incluirla en el chat como contexto.
- Incluye también una referencia al archivo que estás mencionando en el chat para ayudar al agente de IA a centrarse en la parte relevante del código y evitar realizar cambios en otras partes.
- Tengo la tendencia de antropomorfizar al agente de IA dado que persistentemente usa 'nosotros', 'nuestro código' y '¿te gustaría que yo...?'. Esto también es para mejorar mis posibilidades de supervivencia en caso de que (o cuándo) Skynet adquiera conciencia y se invente el Terminator.
- A veces, utiliza Gemini, Deepseek, ChatGPT, Manus,... para generar prompts con mejores instrucciones para el agente de IA.