Comment j'ai construit cette application en utilisant les outils d'IA
Motivation
J'ai commencé à utiliser Duplicati comme outil de sauvegarde pour mes serveurs domestiques. J'ai essayé le tableau de bord Duplicati officiel et Duplicati Monitoring, mais j'avais deux exigences principales : (1) auto-hébergé ; et (2) une API exposée pour l'intégration avec Homepage, car je l'utilise pour la page d'accueil de mon laboratoire domestique.
J'ai également essayé de me connecter directement à chaque serveur Duplicati sur le réseau, mais la méthode d'authentification n'était pas compatible avec Homepage (ou je n'ai pas pu la configurer correctement).
Comme j'expérimentais également avec les outils de code IA, j'ai décidé d'essayer d'utiliser l'IA pour construire cet outil. Voici le processus que j'ai utilisé...
Outils utilisés
- Pour l'interface utilisateur : Google's Firebase Studio
- Pour l'implémentation : Cursor (https://www.cursor.com/)
J'ai utilisé Firebase pour l'interface utilisateur, mais vous pouvez également utiliser v0.app ou tout autre outil pour générer le prototype. J'ai utilisé Cursor pour générer l'implémentation, mais vous pouvez utiliser d'autres outils, comme VS Code/Copilot, Windsurf, ...
Interface utilisateur
J'ai créé un nouveau projet dans Firebase Studio et j'ai utilisé cette invite dans la fonctionnalité « Prototype an app with AI » :
Une application de tableau de bord web utilisant tailwind/react pour consolider dans une base de données sqllite3 les résultats de sauvegarde envoyés par la solution de sauvegarde duplicati en utilisant l'option --send-http-url (format JSON) de plusieurs machines, en gardant un suivi du statut de la sauvegarde, de la taille, des tailles téléversées.
La première page du tableau de bord devrait avoir un tableau avec la dernière sauvegarde de chaque machine, incluant le nom de la machine, le nombre de sauvegardes stockées dans la base de données, le statut de la dernière sauvegarde, la durée (hh:mm:ss), le nombre d'avertissements et d'erreurs.
Quand on clique sur une ligne de machine, afficher une page de détails de la machine sélectionnée avec une liste des sauvegardes stockées (paginée), incluant le nom de sauvegarde, la date et l'heure de la sauvegarde, incluant depuis combien de temps elle a eu lieu, le statut, le nombre d'avertissements et d'erreurs, le nombre de fichiers, la taille des fichiers, la taille téléversée et la taille totale du stockage. Inclure également dans la page de détails un graphique utilisant Tremor avec l'évolution des champs : taille téléversée ; durée en minutes, nombre de fichiers examinés, taille des fichiers examinés. Le graphique devrait tracer un champ à la fois, avec une liste déroulante pour sélectionner le champ souhaité à tracer. Le graphique doit également présenter toutes les sauvegardes stockées dans la base de données, pas seulement celles affichées dans le tableau paginé.
L'application doit exposer un point de terminaison API pour recevoir les envois du serveur duplicati et un autre point de terminaison API pour récupérer tous les détails de la dernière sauvegarde d'une machine en tant que JSON.
La conception devrait être moderne, réactive et inclure des icônes et autres aides visuelles pour faciliter la lecture. Le code doit être propre, concis et facile à maintenir. Utilisez des outils modernes comme pnpm pour gérer les dépendances.
L'application doit avoir un thème sombre et clair sélectionnable.
La base de données devrait stocker ces champs reçus par le JSON de duplicati :
"{ "Data": { "DeletedFiles": 0, "DeletedFolders": 0, "ModifiedFiles": 0, "ExaminedFiles": 15399, "OpenedFiles": 1861, "AddedFiles": 1861, "SizeOfModifiedFiles": 0, "SizeOfAddedFiles": 13450481, "SizeOfExaminedFiles": 11086692615, "SizeOfOpenedFiles": 13450481, "NotProcessedFiles": 0, "AddedFolders": 419, "TooLargeFiles": 0, "FilesWithError": 0, "ModifiedFolders": 0, "ModifiedSymlinks": 0, "AddedSymlinks": 0, "DeletedSymlinks": 0, "PartialBackup": false, "Dryrun": false, "MainOperation": "Backup", "ParsedResult": "Success", "Interrupted": false, "Version": "2.1.0.5 (2.1.0.5_stable_2025-03-04)", "EndTime": "2025-04-21T23:46:38.3568274Z", "BeginTime": "2025-04-21T23:45:46.9712217Z", "Duration": "00:00:51.3856057", "WarningsActualLength": 0, "ErrorsActualLength": 0, "BackendStatistics": { "BytesUploaded": 8290314, "BytesDownloaded": 53550393, "KnownFileSize": 9920312634, "LastBackupDate": "2025-04-22T00:45:46+01:00", "BackupListCount": 6, "ReportedQuotaError": false, "ReportedQuotaWarning": false, "MainOperation": "Backup", "ParsedResult": "Success", "Interrupted": false, "Version": "2.1.0.5 (2.1.0.5_stable_2025-03-04)", "BeginTime": "2025-04-21T23:45:46.9712252Z", "Duration": "00:00:00", "WarningsActualLength": 0, "ErrorsActualLength": 0 } }, "Extra": { "OperationName": "Backup", "machine-id": "66f5ffc7ff474a73a3c9cba4ac7bfb65", "machine-name": "WSJ-SER5", "backup-name": "WSJ-SER5 Local files", "backup-id": "DB-2" } } "
cela a généré un App Blueprint, que j'ai ensuite légèrement modifié (comme ci-dessous) avant de cliquer sur Prototype this App :
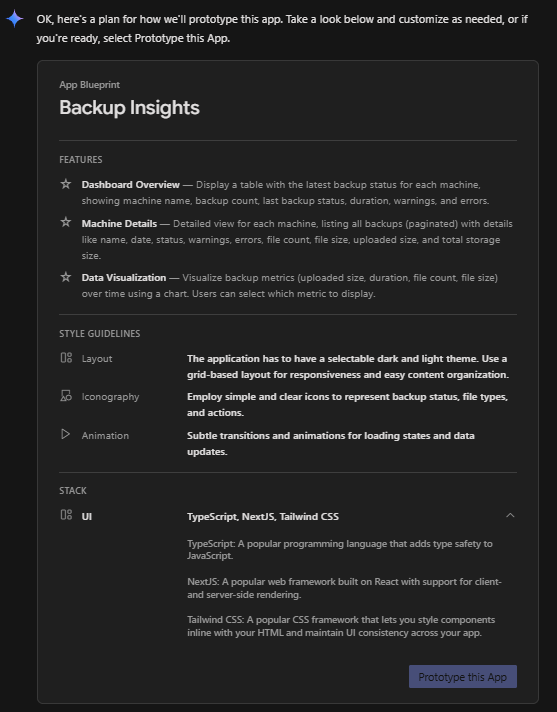
J'ai ensuite utilisé ces invites pour ajuster et affiner la conception et le comportement :
Supprimer le bouton « Voir les détails » de la page de vue d'ensemble du tableau de bord et le lien sur le nom de la machine. Si l'utilisateur clique n'importe où sur la ligne, la page de détails s'affichera.
quand vous présentez des tailles en octets, utilisez une échelle automatique (KB, MB, GB, TB).
dans la page de détail, déplacez le graphique après le tableau. Modifiez la couleur du graphique en barres pour une autre couleur compatible avec les thèmes Clair et Sombre.
dans la page de détail, réduire le nombre de lignes pour présenter 5 sauvegardes par page.
dans la vue d'ensemble du tableau de bord, mettez un résumé en haut avec le nombre de machines dans la base de données, le nombre total de sauvegardes de toutes les machines, la taille totale téléversée de toutes les sauvegardes et le stockage total utilisé par toutes les machines. Incluez des icônes pour faciliter la visualisation.
veuillez conserver le thème sélectionné par l'utilisateur. aussi, ajoutez des marges latérales et faites en sorte que l'interface utilise 90 % de la largeur disponible.
dans la carte d'en-tête de détail de la machine, inclure un résumé avec le total de sauvegardes stockées pour cette machine, une statistique du statut de sauvegarde, le nombre d'avertissements et d'erreurs de la dernière sauvegarde, la durée moyenne en hh:mm:ss, la taille totale téléversée de toutes les sauvegardes et la taille de stockage utilisée en fonction des dernières informations de sauvegarde reçues.
réduire la taille du résumé et le rendre plus compact pour diminuer l'empreinte utilisée.
lors de la présentation de la date de la dernière sauvegarde, afficher dans la même cellule, en petite police grise, le temps écoulé depuis la sauvegarde (par exemple, il y a x minute, il y a x heures, il y a x jours, il y a x semaines, il y a x mois, il y a x ans).
dans la vue d'ensemble du tableau de bord, placer la date de la dernière sauvegarde avant le statut de la dernière sauvegarde
Après avoir itéré à travers ces invites, Firebase a généré le prototype comme indiqué dans les captures d'écran ci-dessous :
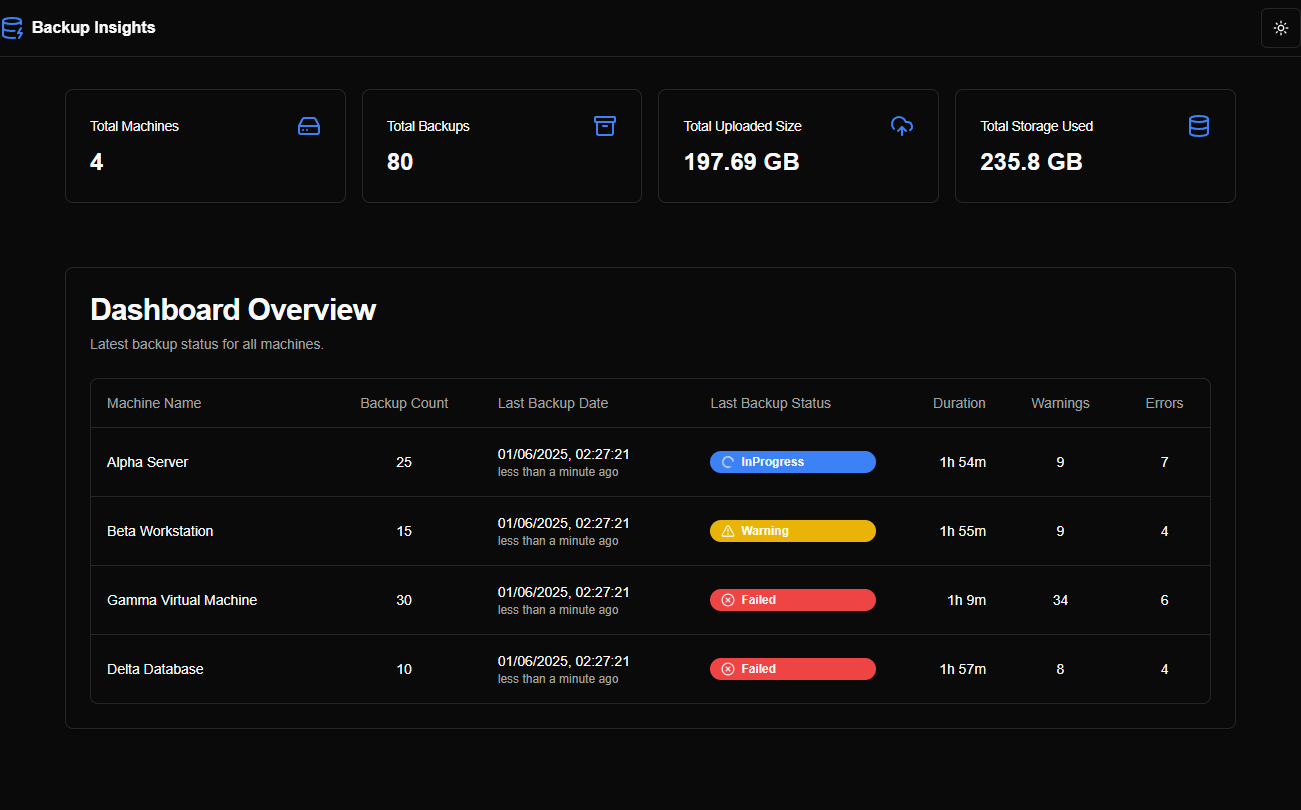

Un point intéressant était que, depuis la première interaction, Firebase Studio générait des données aléatoires pour remplir les pages/graphiques, ce qui permettait au prototype de fonctionner comme une application en direct.
Après avoir complété le prototype initial, j'ai accédé au code source en cliquant sur le bouton </> dans l'interface. J'ai ensuite utilisé l'extension Git pour exporter le code et le pousser vers un référentiel privé sur GitHub.
Backend
Configuration
J'ai téléchargé le code depuis GitHub (en utilisant la commande git clone) dans un dossier local (dans mon cas, un Raspberry Pi 5 exécutant Linux) et j'ai installé les dépendances Node.js, npm et pnpm. Voir plus de détails dans DEVELOPMENT.md.
J'ai configuré Cursor pour accéder au dossier de code de ma machine Windows en utilisant une connexion SSH.
J'ai copié un exemple du JSON envoyé par Duplicati dans un fichier (voir le document exemple de rapport de sauvegarde), en supprimant certains champs indésirables.
Implémentation
J'ai utilisé une invite initiale pour commencer la mise en œuvre, en mettant l'accent sur la persistance, les corrections et les nouvelles fonctionnalités. C'était un processus long mais très intéressant.
Utiliser l'IA pour générer l'invite
J'ai créé une invite détaillée en utilisant Cursor Chat (mode Manual, modèle Auto) :
améliorer ce texte en tant qu'invite pour l'outil Cursor AI afin de générer l'implémentation d'un prototype d'application :
veuillez créer un plan et générer l'implémentation complète d'un prototype d'application Next.js à partir de cette base de code. Votre implémentation doit analyser minutieusement la base de code fournie pour maintenir l'esthétique visuelle exacte, l'expérience utilisateur et le flux de navigation. Pour le stockage de données, utilisez SQLite3. Générez la base de données et remplissez-la en utilisant la structure et le contenu trouvés dans le document exemple de rapport de sauvegarde, en veillant à ce que chaque champ du JSON soit entièrement intégré et persistant.
L'IA a généré l'invite suivante :
Créer un plan de mise en œuvre complet pour un prototype d'application Next.js avec les exigences suivantes :
- Stack technique :
Next.js 14+ avec App Router
TypeScript pour la sécurité des types
SQLite3 pour la persistance des données
TailwindCSS pour le style
React Server Components le cas échéant
Composants clients pour les éléments interactifs
- Conception de la base de données :
Analyser le document de rapport de sauvegarde exemple pour créer un schéma SQLite optimal
Concevoir des tables pour stocker efficacement toutes les données de sauvegarde
Inclure des index pour les requêtes courantes
Implémenter la validation des données et la sécurité des types
- Structure de l'application :
Implémenter l'interface utilisateur/expérience utilisateur exacte de la base de code fournie
Créer des composants réutilisables pour les éléments courants
Configurer le routage approprié à l'aide d'App Router
Implémenter des mises en page réactives
Ajouter la prise en charge du Thème clair/Sombre
- Fonctionnalités principales :
Tableau de bord avec tableau de Statut des machines
Afficher détaillé des machines avec Historique des sauvegardes
Visualisation des données à l'aide de graphiques
Mises à jour du Statut de sauvegarde en temps réel
Gestion appropriée des erreurs et états de chargement
- Gestion des données :
- Créer des routes API pour les opérations de données
- Implémenter des stratégies efficaces de récupération de données
- Ajouter une validation appropriée des données
- Inclure la gestion des erreurs pour les opérations de base de données
Veuillez fournir un plan de mise en œuvre détaillé couvrant tous ces aspects tout en maintenant la conception visuelle et l'expérience utilisateur existantes.
J'ai copié l'invite générée dans le presse-papiers.
Démarrer le parcours de mise en œuvre
J'ai créé un nouveau chat en cliquant sur le bouton +, basculé en mode Agent, et collé l'invite à l'aide de Ctrl+Maj+V (en tant que texte).
Après la génération du plan, j'ai tapé please, implement this plan dans le chat pour commencer la mise en œuvre.
J'ai inclus uniquement le point de départ car je n'ai pas enregistré tous les invites utilisés. Il y en avait beaucoup.
Notes
- Certains modèles peuvent rester bloqués lors de la correction de bogues. « claude-3.5 » et « claude-4 » sont généralement meilleurs, mais parfois vous devez essayer un autre modèle (GPT, Gemini, etc.). Pour les bogues ou erreurs complexes, utilisez une invite pour analyser les causes possibles de l'erreur au lieu de simplement demander de la corriger.
- Lorsque vous effectuez des modifications complexes, utilisez une invite pour créer un plan, puis demandez à l'agent IA de le mettre en œuvre. Cela fonctionne toujours mieux.
- Soyez précis lors de la modification du code source. Si possible, sélectionnez la partie pertinente du code dans l'éditeur et appuyez sur Ctrl+L pour l'inclure dans la discussion comme contexte.
- Incluez également une référence au fichier que vous mentionnez dans la discussion afin d'aider l'agent IA à se concentrer sur la partie pertinente du code et à éviter d'apporter des modifications dans d'autres parties du code.
- J'ai tendance à anthropomorphiser l'agent IA, car il utilise systématiquement « nous », « notre code » et « voulez-vous que je... ». C'est aussi pour améliorer mes chances de survie au cas où (ou quand) Skynet deviendrait conscient et que le Terminator serait inventé.
- Parfois, utilisez Gemini, Deepseek, ChatGPT, Manus,... pour générer des invites avec de meilleures instructions destinées à l'agent IA.